
Apache Hudi does XYZ (1/10)
File pruning with multi-modal index

Apache Hudi has a ton of awesome features, but honestly, the sheer number of them can feel pretty overwhelming when you're just starting out. That's why I'm putting together this 10-post blog series—to break down all those capabilities and highlight some of the coolest features in Hudi 1.0, which is a huge milestone release that really pushes Hudi toward being a full-fledged Data Lakehouse Management System.
Think of this series as the follow-up to my earlier "Apache Hudi: From Zero To One" series, where I dove deep into Hudi's design concepts based on version 0.x. The good news is that almost everything from that earlier series still applies to Hudi 1.x, so it's still great for building a solid foundation—in fact, I'd highly recommend reading through that series first, or checking out the consolidated e-book version available at this link. While that earlier series was pretty heavy on concepts and internals, this one's going to be different. I'm aiming for a good mix of theory and practical stuff—complete with sample code and real examples you can actually use. My goal is to help you not just understand what makes Hudi so powerful, but get you up and running with these features quickly through hands-on, practical guidance.
Let's start with one of Hudi's core performance features: the multi-modal index and file pruning. This is what makes your queries fast by helping engines figure out exactly which files to read and which ones to skip entirely.
The Multi-Modal Index in Hudi
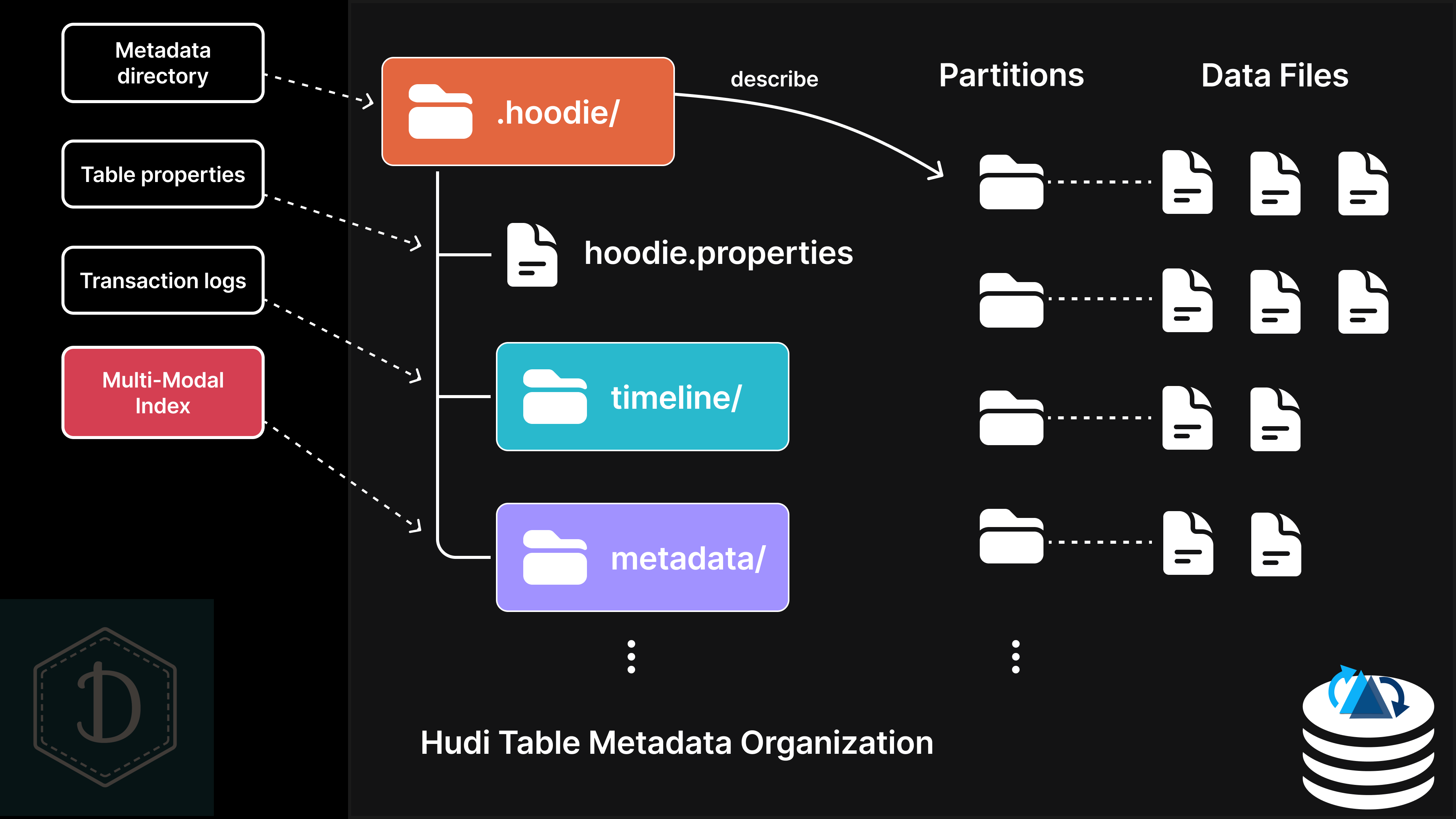
Every data lakehouse table—whether it uses Delta, Hudi, or Iceberg—contains a metadata directory that describes the data stored in that table. For Hudi tables, this is the .hoodie/ directory, and you can learn more about Hudi's complete storage layout (including this metadata directory) in this post.
Hudi's multi-modal index lives within the .hoodie/metadata/ directory and has an interesting design: it's actually implemented as its own Hudi Merge-on-Read table, known as the metadata table. This metadata table gets updated synchronously alongside any write operations to your main data table, ensuring everything stays consistent and in sync.
Indexing is what separates a good lakehouse table from a great one—it can make or break your read and write performance. The challenge is that different queries need different types of indexes: range pruning relies on min/max values, point lookups need exact value matching, and vector searches use similarity calculations to find the closest matches. There's no single "one-size-fits-all" index that can handle everything efficiently.
That's why lakehouse tables need versatile indexing capabilities to perform well across all kinds of workloads. Hudi was actually a pioneer in this space, introducing the multi-modal index back in version 0.11 in 2022. The "multi-modal" name reflects how the underlying metadata table is partitioned by different index types, with each index using its own record schema designed for its specific purpose.
Files, Partitions, and Statistics
When you have a collection of columnar files like Parquet stored somewhere, partitioning by some columns at the physical storage level is the best indexing you can get without a lakehouse format—but it's also very coarse-grained and basic. Here's where it gets limiting: if your table is partitioned by column A and someone runs a query filtering on column B (like "find all records where column B > X"), the query engine can't do much optimization. It still has to list all partitions and files, then scan through and filter all the records.
When you create a table in Hudi 1.x, three essential indexes are automatically enabled in the metadata table: files, partition_stats, and column_stats. These indexes provide the core information that query engines need to plan and execute queries efficiently. For more details about how query engines work with Hudi tables, check out this earlier post.
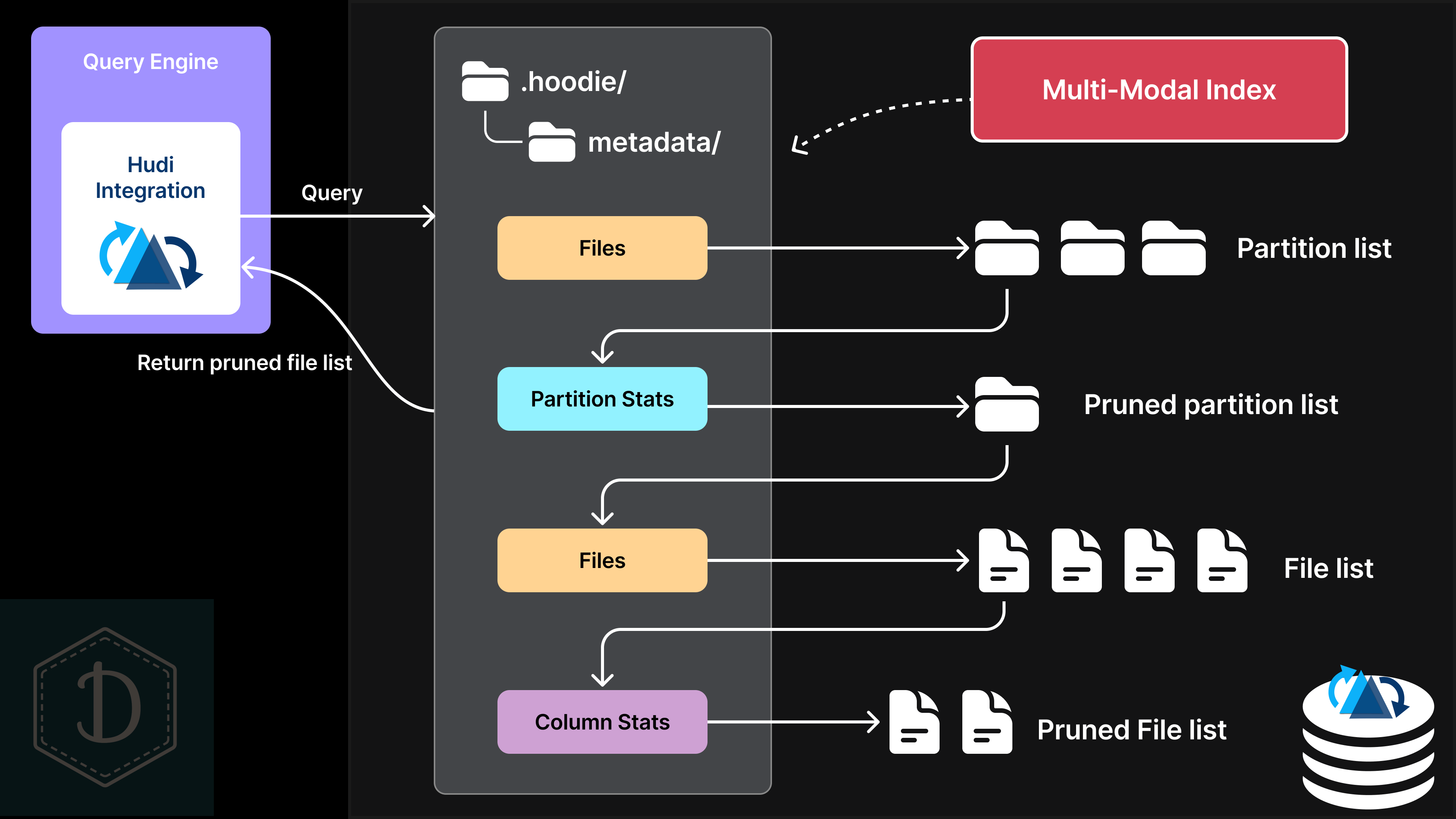
When we say a query engine "supports Hudi," it means the engine has a component that understands Hudi's table layout, including how to read from the metadata table. Here's how the query planning process works:
First, the query engine reads the files index to get a list of partitions to examine. Then it uses the partition_stats index to prune that list by comparing your query predicates against partition-level statistics like min, max, and count values. For example, if your query is looking for records where price >= 300, any partitions with a max price below 300 can be completely skipped.
With the pruned partition list in hand, the engine goes back to the files index to get the actual file lists for each remaining partition. But it's not done yet—it can prune those file lists even further using the column_stats index, which provides the same kind of statistics but at the file level instead of the partition level.
This multi-layered pruning process means the query engine only reads the files it actually needs, significantly reducing the amount of data it has to process.
Running in Spark SQL
Let's see file pruning in action by creating a Hudi table with sample data and running some Spark SQL queries. We'll start by creating a table with both partition_stats and column_stats disabled to establish a baseline.
CREATE TABLE order (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'shipping_date',
hoodie.metadata.index.column.stats.enable = 'false',
hoodie.metadata.index.partition.stats.enable = 'false'
);And insert some sample data:
INSERT INTO order VALUES
('ORD001', 389.99, 'PENDING', 17495166353, DATE('2023-01-01'), 'A'),
('ORD002', 199.99, 'CONFIRMED', 17495167353, DATE('2023-01-01'), 'A'),
('ORD003', 59.50, 'SHIPPED', 17495168353, DATE('2023-01-11'), 'B'),
('ORD004', 99.00, 'PENDING', 17495169353, DATE('2023-02-09'), 'B'),
('ORD005', 19.99, 'PENDING', 17495170353, DATE('2023-06-12'), 'C'),
('ORD006', 5.99, 'SHIPPED', 17495171353, DATE('2023-07-31'), 'C');The query for our test is as below:
SELECT order_id, price, shipping_country
FROM order
WHERE price > 300;This query looks for orders with price greater than 300, which only exist in the partition of shipping_country=A. After running the SQL, here's what we see in the Spark UI:

Spark read all 3 partitions and 3 files to find potential matches, but only 1 record from partition A actually satisfied the query condition.
Enable column_stats
Now let's enable column_stats while keeping partition_stats disabled. Note that we can't do it the other way around—partition_stats requires column_stats to be enabled first.
CREATE TABLE order (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'shipping_date',
hoodie.metadata.index.column.stats.enable = 'true',
hoodie.metadata.index.partition.stats.enable = 'false'
);Running the same SQL gives us this in the Spark UI:

Now it shows all 3 partitions but only 1 file was scanned. Without partition_stats, the query engine couldn't prune partitions, but column_stats successfully filtered out the non-matching files. The compute cost of examining those 2 irrelevant partitions and their files could have been avoided with partition_stats enabled.
Enable column_stats and partition_stats
Now let's enable partition_stats as well. Since both indexes are enabled by default in Hudi 1.x, we can simply omit those additional configs from the CREATE statement.
CREATE TABLE order (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'shipping_date'
);Running the same SQL gives us this in the Spark UI:

Now we see the full pruning effect happened—only 1 relevant partition and 1 relevant file were scanned, thanks to both indexes working together.
Configure columns to be indexed
By default, Hudi indexes the first 32 columns for both partition_stats and column_stats. This limit prevents excessive metadata overhead—each indexed column requires computing min, max, null-count, and value-count statistics for every partition and data file. In most cases, you only need to index a small subset of columns that are frequently used in query predicates. You can specify which columns to be indexed to reduce the maintenance costs:
CREATE TABLE order (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'update_ts',
'hoodie.metadata.index.column.stats.column.list' = 'price,shipping_date'
);The config hoodie.metadata.index.column.stats.column.list applies to both partition_stats and column_stats. By indexing just the price and shipping_date columns, queries filtering on price comparisons or shipping date ranges will already see significant performance improvements.
Recap
In this post, we explored Hudi's multi-modal index from a storage layout perspective and demonstrated the file pruning capabilities of the three default indexes in Hudi 1.x: files, partition_stats, and column_stats. Through our SQL examples, you can see how these indexes could dramatically reduce the number of files that need to be scanned, which is crucial for query performance.
In upcoming posts, we'll explore the multi-modal index's additional capabilities and discuss how its design benefits not just performance, but also scalability, extensibility, and maintenance.