
Building a RAG-based AI Recommender (1/2)
What is RAG, and how to go from data to AI.

You run an online shopping website that sells approximately 100,000 products, and you want to add a new AI recommender to help your website visitors find their desired products by answering questions like "I'm looking for headphones for swimming with a great value-to-price ratio." With new products being listed daily, old products being removed regularly, and sellers updating product details throughout the day, you need to ensure your AI recommender provides accurate and up-to-date information for your users. This scenario is perfectly suited for a RAG-based AI application with incremental processing capabilities provided by an Apache Hudi lakehouse.
In this two-part blog, I'll structure the content as follows:
Part 1: I'll introduce RAG from a conceptual perspective and explore why solid data architecture is crucial for AI success.
Part 2: We'll get hands-on with working code and demonstrate the complete end-to-end flow of an AI recommender.
By the end of this two-part blog series, you'll have a solid understanding of RAG basic concepts and know how to build AI apps. You'll get hands-on experience running incremental queries on Hudi tables, building vector search indexes with Qdrant, and setting up a FastAPI app that handles user questions and connects to OpenAI—so you can see a complete working example in action.
RAG is gonna be Ubiquitous
Retrieval-Augmented Generation (RAG) has emerged as the dominant paradigm for building AI applications that need to work with private or domain-specific data. At its core, RAG consists of two essential steps: retrieval and generation. While Large Language Models (LLMs) possess impressive general knowledge, they don't know anything about your company's internal documents, customer data, or proprietary information. RAG solves this by first retrieving relevant pieces of your private data based on a user's query, then feeding this context to the LLM for generation. This approach allows the model to ground its responses in your specific data, transforming a general-purpose AI into a knowledgeable assistant that can reason about your unique business context.
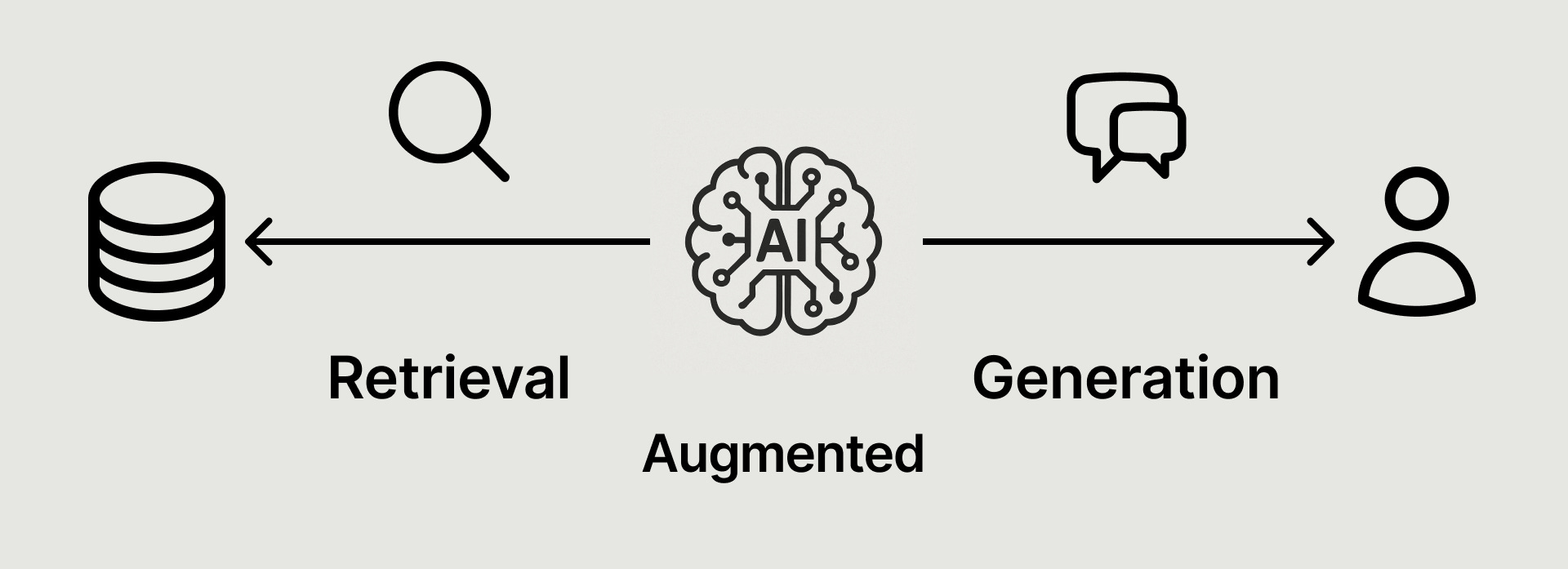
RAG is set to become ubiquitous because it solves a real problem every organization faces: how to make AI work with their specific data. Companies have tons of proprietary information—internal docs, customer records, product manuals—that could make AI incredibly useful if the models could actually access it. RAG provides a practical way to connect your existing data with powerful LLMs, putting AI that understands your business context within reach of most organizations. As more businesses realize they can get contextually aware AI with manageable engineering effort, RAG adoption will continue to explode.
Data Preparation
Before you can retrieve relevant information, your data needs to be transformed into a format that machines can efficiently search and understand. This preparation process involves two critical steps that lay the foundation for effective retrieval.
Chunking
The first step involves splitting your data into manageable chunks. This chunking process is essential because you don't want to retrieve massive documents for the LLM to process—there are limits on the context window that LLMs can effectively work with. Each chunk should contain enough context to be meaningful on its own while remaining small enough to fit comfortably within the LLM's processing capabilities. Choosing a good chunking strategy—whether by paragraphs, sentences, or semantic boundaries—is critical for improving your RAG system's efficiency and accuracy.
Embedding
Once your data is chunked, the next step involves converting these chunks into vectors using an embedding model. Vectors are arrays of numbers that encode human-understandable information into a machine-understandable format, where the dimensions work together to encode semantic meaning in complex patterns. To understand this concept, imagine a 3D vector in a coordinate system representing a point in space, where each element represents distances on the x, y, and z axes. Similarly, text embeddings use hundreds or thousands of dimensions to mathematically compare the similarity of different text chunks, even when they use completely different words to express similar concepts.
Retrieval
The retrieval process takes your prepared data and finds the most relevant pieces to answer a user's query. This involves converting the user's question into the same vector format and then searching your knowledge base for similar content.

With all your data chunks converted to vectors and stored in a vector database, it's time to retrieve the ones most relevant to a user's query. The user's question first gets converted into a vector using the same embedding model that processed your data chunks. Then, similarity functions calculate how close this query vector is to each stored vector in your database. Common similarity functions include cosine similarity, Euclidean distance, and dot product—each representing different mathematical approaches to measuring the "distance" between two vectors in high-dimensional space. Vector databases support these calculations out-of-the-box and can quickly return the top-k most similar vectors along with their associated original data chunks. These retrieved chunks then serve as the contextual foundation for the LLM to generate its response.
Re-ranking
In practice, retrieval typically involves a two-stage process. After the initial vector database search, there's an additional step called re-ranking that significantly improves accuracy. Re-ranking uses a cross-encoder model to perform a more sophisticated comparison between the user's query and the candidates returned by the vector database. While the distance-based similarity search is fast and efficient, it's not always precise in capturing semantic relevance. Cross-encoder models, though more computationally intensive, provide much more accurate similarity assessments. This two-stage approach dramatically boosts overall retrieval accuracy while maintaining good performance.
Generation
Once the retrieval process identifies and refines the most relevant context from your datasets, the generation step becomes relatively straightforward. You combine the retrieved context with the user's original query and send this information to an LLM via API calls, which then returns a response to the user.

In practice, you'll typically compose the context information and user query into a prompt template. This template allows you to specify detailed instructions for the LLM to follow, tailoring the response format, tone, and focus to match your specific business needs. For example, you might instruct the model to cite sources, maintain a professional tone, or format answers in a particular structure that aligns with your application's requirements.
From Data to AI
Now you have gone through the end-to-end flow of a RAG system, but it's still not the full picture of reality. Where do you gather and store the data for chunking? Your data is changing dynamically—how do you deal with updates to ensure your RAG apps are using up-to-date data? And what if the data contains noise that could cause your system to send misleading information to users? There is no shortcut here: a solid data platform serving high-quality data is the pre-requisite to fully utilizing AI's power.
Without a proper data infrastructure, even the most sophisticated LLM models can't reach their full potential—it's the classic "garbage in, garbage out" principle that still holds true in the age of AI. To fully harvest the fruits your RAG apps can offer, you'll likely spend a significant portion of your efforts—sometimes around 70%—on data engineering: ingesting and cleaning data, scaling clusters appropriately, setting up monitoring and alert systems, and managing access. These efforts ensure that you have an efficient, reliable, and business-ready data source for AI applications.
“Garbage In, Garbage Out”
Data quality fundamentally defines the lower bound of your AI inference results. No matter how sophisticated your models are, poor-quality input data will inevitably lead to subpar AI performance. This becomes even more critical in RAG systems, where AI responses are directly grounded in the retrieved information.
The medallion architecture provides a foundation to build quality control mechanisms, systematically refining data through bronze, silver, and gold layers. See this previous blog. Raw data often contains inconsistencies, duplicates, and formatting issues that lead to embeddings calculated from bad data, resulting in poor retrieval accuracy. The gold layer provides business-ready, curated datasets perfect for AI consumption. Even for unstructured binary data like images and videos, you'll want structured tables in the gold layer to track properly formatted metadata for them, enabling LLMs to have more accurate context for generating high-quality responses.
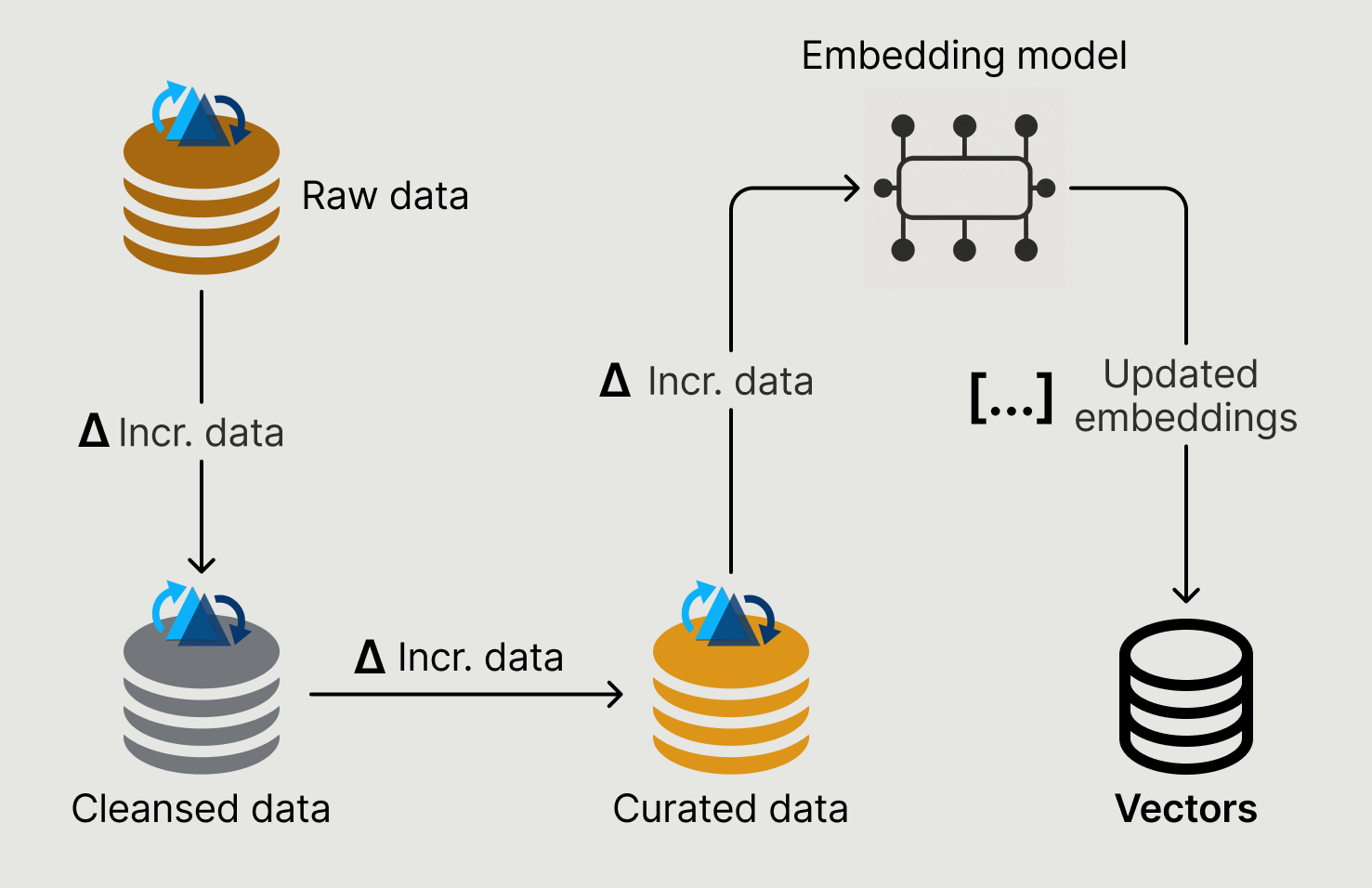
AI applications are also compute-intensive—from semantic chunking to calculating embeddings, from performing similarity searches to querying LLMs for response generation—each step involves heavy compute resources and significant costs. This makes two things essential: first, ensuring the data you put through this process is high-quality and worth the compute investment; second, running the process only on changes that affect the system. Rather than reprocessing entire table snapshots, you should work with incremental changes to update just a subset of all the embeddings.
Why Hudi for Incremental Processing?
Hudi was designed with incremental processing in mind from day one. Hudi's timeline essentially tracks changes made to the table, and through commit files, we can easily fetch the files that contain changes during a specific time window. With the relevant files identified, Hudi uses the record-level meta field _hoodie_commit_time to further filter down the records to be returned. The detailed design discussion can be found in this post.
This timeline and record-level filtering mechanism makes Hudi tables perfectly suitable for the medallion architecture, where changes propagate through multiple layers. The same semantics of incremental processing can be applied throughout your data lakehouse as a standard practice, establishing good data engineering and architecture patterns that make data operations and maintenance easier.
Looking into the future, Hudi has also made roadmap plans to include vector search index support out-of-the-box, which will further simplify the architecture across the entire data storage layer. You'll be able to incrementally calculate embeddings and store them in a Hudi table, then perform similarity searches with Hudi readers. This creates a more unified reader and writer stack for your data architecture.
Recap
In this first part of the blog, we've introduced RAG at a conceptual level by walking through the end-to-end flow. We've also discussed the importance of good data architecture for AI applications and how Hudi's incremental processing capabilities can support such architecture. In part 2, we'll go through an end-to-end implementation of RAG, building the AI recommender example that we introduced at the beginning of this blog.
Follow me on LinkedIn and X for more updates.
when is the next part coming out? love it!
Great article!
Looking forward to the next part.