
Building a RAG-based AI Recommender (2/2)
An end-to-end code walkthrough.

In part 1 of this blog, we explored the core concepts of Retrieval-Augmented Generation (RAG) and how Apache Hudi's incremental processing capabilities provide a critical foundation for an efficient RAG data pipeline.
In this post, we'll move from theory to practice with a hands-on example, building an end-to-end demo RAG application from the ground up.
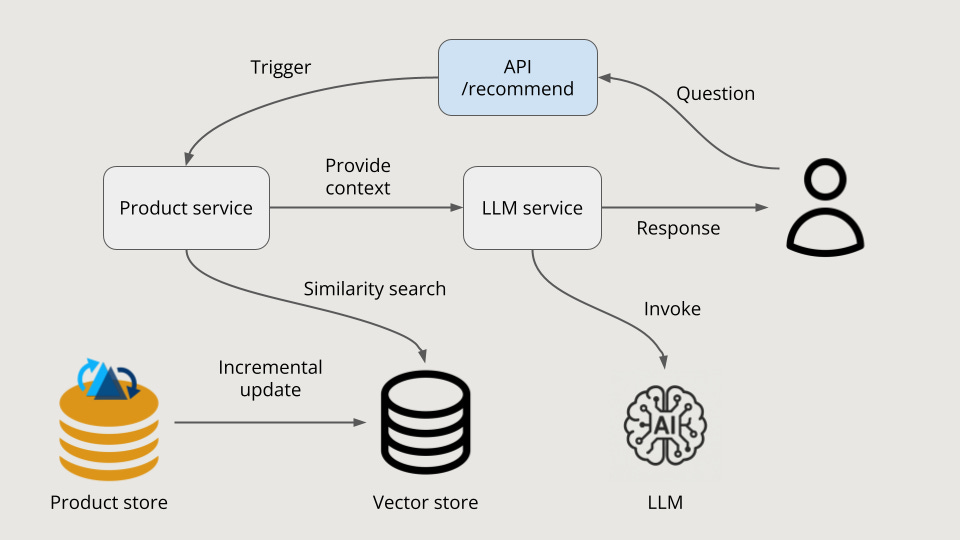
Workflow Overview
As illustrated in the figure below, our RAG application consists of five main components:
User-Facing API: The primary interface for the recommendation service.
Product Service (Retrieval): For our e-commerce use case, this service manages access to and updates of product information. It represents the "retrieval" phase of RAG.
LLM Service (Generation): This service builds context from the retrieved product information and connects to an LLM to generate user-facing responses. This constitutes the "generation" phase.
Product Store: A Hudi table that stores the primary product information, which is built incrementally and serves as the single source of truth.
Vector Store: Responsible for storing product information embeddings and handling similarity search requests from the Product Service.
For the user-facing API, we define an async endpoint, /recommend, to handle incoming requests. This endpoint processes natural language queries from users and uses product and LLM services to retrieve context and generate response. It also runs a periodic sync task that incrementally reads the latest product information from the Product Store, converts it to vectors, and upserts them into the vector store to keep it up-to-date.
The product service is responsible for embedding the user's query and performing a similarity search on the vector store. When the similarity search returns relevant product information, the Product Service passes this context to the LLM Service.
The LLM service then uses this context to compose a prompt, which it sends to an LLM API. Once a response is generated, the service formats it and delivers the final API response to the user.
Let's now examine each step, highlighting the key code snippets involved.
API Server
We use FastAPI to quickly prototype the API endpoint /recommend as:
@app.post("/recommend")
async def get_recommendations(request: RecommendationRequest) -> dict:
return recommendation_service.get_recommendations(request.query)Also define a background sync task to be run periodically while the server app is running, keeping the vector store up-to-date:
async def background_sync(svc: RecommendationService):
while True:
try:
logger.info("Starting background sync...")
svc.sync_data_source()
logger.info("Background sync completed")
except Exception as e:
logger.error(f"Background sync failed: {e}")
await asyncio.sleep(config.update_interval)Hudi Incremental Read
The sync_data_source() function leverages the Hudi-rs library—a native Rust implementation of Hudi—to incrementally read from the products table. The key snippet below shows how we initialize the Hudi table and perform an incremental read:
# Initialize the Hudi table from its base path
hudi_table = HudiTableBuilder.from_base_uri(
config.hudi_table_path
).build()
# Perform an incremental read starting from the last sync timestamp
incr_batches = hudi_table.read_incremental_records(start_ts, None)The start_ts parameter is set to the timestamp of the last sync, which is maintained as a property within the product service. This ensures that only new or updated records are fetched during each cycle, making the data sync process highly efficient.
Upsert Embeddings
To prepare the product data for the vector store, we first need to process the raw text. The product names and descriptions must be broken down into smaller, semantically meaningful 'chunks.' This is a crucial step because embeddings are more effective when generated from concise, focused pieces of text.
While chunking strategies can be quite complex and highly dependent on the data, we'll use the semantic-text-splitter library for this demo. It allows us to divide the text into coherent semantic units. In the code, we define a SemanticChunker with configurable settings to handle this process.
from semantic_text_splitter import TextSplitter
class SemanticChunker:
def __init__(self):
self.splitter = TextSplitter(
capacity=config.max_chunk_tokens,
overlap=config.chunk_overlap_tokens,
)Once the text is chunked, the next step is to convert these chunks into numerical representations called embeddings. For this, we use the powerful SentenceTransformers library, which transforms each text chunk into a dense vector (as a NumPy array) that captures its semantic meaning.
class EmbeddingService:
def __init__(self):
self.model = SentenceTransformer(config.embedding_model)
def create_embeddings(
self, chunks: list[ProductChunk]
) -> np.ndarray:
texts = [chunk.content for chunk in chunks]
return self.model.encode(
texts, convert_to_tensor=True
).cpu().numpy()For the vector store, we chosen Qdrant, a high-performance vector database. The embedding arrays are packaged into PointStruct objects—Qdrant's primary data structure—before being saved into a collection.
class VectorStore:
def __init__(self):
self.client = QdrantClient(":memory:")
self.collection_name = "products"
def upsert(
self, chunks: list[ProductChunk], embeddings: np.ndarray
):
points = [
PointStruct(
id=chunk.chunk_id,
vector=embeddings[i] * chunk.importance_score,
payload={
"product_id": chunk.product_id,
"content": chunk.content,
"importance_score": chunk.importance_score,
},
)
for i, chunk in enumerate(chunks)
]
self.client.upsert(
collection_name=self.collection_name,
points=points,
wait=False,
)This process of combining incremental reads with vector upserts ensures that the vector store remains synchronized with the latest product information, making it ready for accurate similarity searches.
Product Service
When a user query is received, the product service uses the same embedding model to encode the query into a vector. It then performs a similarity search against the vector store to retrieve the top-K most relevant product chunks.
class VectorStore:
def __init__(self):
self.client = QdrantClient(":memory:")
self.collection_name = "products"
def search(self, query_vector: np.ndarray) -> list[ProductChunk]:
top_k = int(config.vector_search_top_k)
results = self.client.search(
collection_name=self.collection_name,
query_vector=query_vector,
limit=top_k,
score_threshold=config.similarity_threshold,
)Because each chunk is associated with a product ID, the service can reconstruct a list of relevant product information from the search results. This list forms the context that is passed to the LLM Service for the final generation step.
LLM Service
The LLM service receives the list of ProductSearchResult objects from the product service to use as context. It then composes a prompt incorporating this information and sends it to the connected AI service provider (in this case, OpenAI).
class LLMService:
def __init__(self):
import openai
self.client = openai.OpenAI(api_key=config.openai_api_key)
def generate_recommendation(
self,
query: str,
matching_products: list[ProductSearchResult],
) -> str:
"""Generate recommendations with chunk context"""
context = self._prepare_context(matching_products)
prompt = f"""
User Query: {query}
Based on these context:
{context}
(End of context)
Instructions:
1. Provide product recommendations to the user with brief explanations.
2. Only recommend the products shown in the context.
3. Do not mention the product IDs in the recommendations.
"""
try:
response = self.client.chat.completions.create(
model=config.openai_model,
messages=[
{
"role": "system",
"content": "You are a helpful e-commerce recommendation assistant.",
},
{"role": "user", "content": prompt},
],
max_tokens=1000,
temperature=0.7,
)
return response.choices[0].message.content or ""
except Exception as e:
logger.error(f"LLM generation failed: {e}")
return "Unable to generate recommendations at the moment."Once OpenAI returns a response, the LLM service forwards it to the main recommendation service, which formats and delivers the final API response to the user.
Test Run
To test the end-to-end workflow, we first need a Hudi table populated with sample e-commerce product data. The schema can be minimal, as the key information is contained in the name and description columns.
First, create the Hudi table using Spark SQL:
CREATE TABLE products (
id BIGINT,
ts BIGINT,
name STRING,
description STRING
) USING HUDI
TBLPROPERTIES (
primaryKey = 'id',
preCombineField = 'ts'
);Next, insert some realistic sample products into the table. Also, set your OpenAI secret key as an environment variable: OPENAI_API_KEY.
Now, you can start the API server by running ./uvicorn.sh. Upon startup, the application will bootstrap the vector store with the initial records from the Hudi table. As you upsert more records into the Hudi table, the periodic sync process will incrementally process these changes and keep the vector store up-to-date.
To test the API, issue a sample e-commerce query to the endpoint, like: "I like drinking coffee and listening to music with a wireless headphone."
➜ curl -X POST "http://localhost:8000/recommend" \
-H "Content-Type: application/json" \
-d '{"query": "I like drinking coffee and listening to music with wireless headphone"}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 2483 100 2401 100 82 409 13 0:00:06 0:00:05 0:00:01 516
{
"success": true,
"query": "I like drinking coffee and listening to music with wireless headphone",
"message": "Based on your love for coffee and music, here are two product recommendations that would enhance your experience:\n\n1. **Wireless Bluetooth Headphones**: Enjoy your coffee while immersing yourself in premium audio quality with these state-of-the-art wireless headphones. They feature active noise cancellation, a long battery life of 30 hours, and comfortable padding, making them perfect for listening to music without distractions. The water-resistant design also means you can wear them while enjoying your coffee outdoors or during workouts.\n\n2. **Programmable Coffee Maker**: Elevate your coffee experience with this professional-grade stainless steel coffee maker. It offers programmable brewing options and a thermal carafe that keeps your coffee hot for hours. With features like a brew strength selector and a self-cleaning function, you can enjoy a perfect cup of coffee tailored to your taste, all while you relax and listen to your favorite tunes. \n\nThese products will complement your routines beautifully!",
"products": [
{
"id": 1001,
"matched_content": [
"Experience premium audio quality with these state-of-the-art wireless Bluetooth headphones. Featuring active noise cancellation technology, 30-hour battery life, and premium comfort padding. Perfect for music lovers, commuters, and professionals who demand crystal-clear sound quality. The headphones include a portable charging case, multiple ear tip sizes, and support for high-resolution audio codecs. Compatible with all major devices including smartphones, tablets, and laptops. Water-resistant design makes them ideal for workouts and outdoor activities."
]
},
{
"id": 1004,
"matched_content": [
"Professional-grade stainless steel coffee maker with programmable brewing options and thermal carafe. Brews up to 12 cups of perfect coffee with precision temperature control and optimal extraction time. Features include auto-start timer, brew strength selector, and self-cleaning function. The thermal carafe keeps coffee hot for hours without a heating plate, preserving flavor and aroma. Built-in water filtration system removes impurities for better taste. Compact design fits most kitchen countertops while the sleek stainless steel finish complements any décor. Includes permanent gold-tone filter and measuring scoop."
]
}
]
}The response payload contains the AI-generated recommendation in the message field, along with the most relevant product information retrieved by the product service. You can find the complete, runnable code for this project in this GitHub repository.
Recap
In this ending part of the blog, we successfully built a RAG-based AI recommender for e-commerce, leveraging FastAPI, Apache Hudi, Qdrant, and OpenAI. While this application serves as a comprehensive local demonstration, transitioning to a production environment requires further consideration.
Real-world data is far more complex and varied, which needs significant tuning in several areas, including chunking strategies, embedding model selection, similarity search parameters, and LLM prompt engineering.
Ultimately, the success of any production-grade RAG application hinges on a solid data foundation. A reliable and efficient data lakehouse is not just a prerequisite but the core component for this architecture to thrive.
Follow me on LinkedIn and X for more updates.